![]()
|
|
Learning Agents |
|
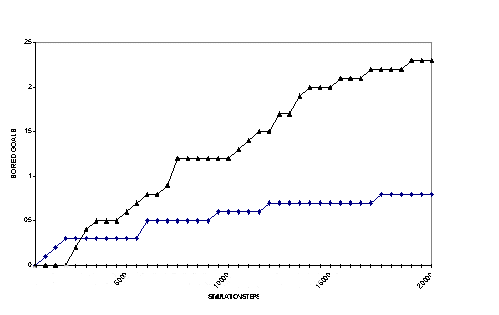
We have faced the problem of adapting the behavior of an autonomous agent to an unknown and complex environment, where other agents are operating. Although this is not a dynamic environment, since we consider that the others are not learning, its complexity is high. We have focused our reactivity on adapting the behavior of a Robocup player to those of the opponents and of its teammates. The agent's behaviors are programmed a priori in the BRIAN environment as sets of fuzzy rules, and a set of blending (WANT) conditions is defined for each behavior. During the match these blending contidions are modified by the learning algorithm to improve the agent's performance. An individual of the population is the pair <W, B>, where W is the set of WANT fuzzy predicates, and B a behavior module. At each control step, the set of triggerable behaviors is evaluated, and for each behavior, an individual is selected with a roulette wheel algorithm. Then, behavior blending is done and the action is executed. When a rewarded event occurs (goal scored, change of ball possession, etc.), reinforcement is distributed to the individuals that have participated to the agent's behavior since last reinforcement evaluation. The reinforcement distribution formula takes into account the time from individual activation and the event, but does not consider eventual future rewards, since the environment is too unpredictable. After reinforcement distribution, individuals with too low reinforcement that have been tested enough are removed, and predicates can be deleted and added to others, maintaining the original individual. We have tested this approach in simulation, since this makes it possible to control the experimental conditions and even to perform a large number experiments that otherwise would require 8 high quality robots and a Robocup MSL field at the same time. From our experiments, we have obtained interesting results. For instance, the number of goals scored by a team where only one robot was adapting its behavior, against another team with a simple strategy where one robot goes on the ball (the closer one) and the others distribute themselves in the field, was significantly increased. In the figure, we show the number of goals scored by the team when a member is learning (higher line) and when it is not learning. The results are averaged on 10 trials.
We are currently experimenting also with our Robocup robots a new approach (LEAP) which can learn in very large state action spaces such as those which arise with multi-robot system, as in Robocup.
Principal investigators
Research contributors
Related Papers
|