![]()
LEAP
Learning in Large Multi-Agent Applications
|
|
LEAPLearning in Large Multi-Agent Applications
|
|
LEAP (Learning Entities Adaptive Partitioning) is a new model-free adaptive reinforcement learning algorithm studied for working in large multi-agent cooperative tasks. In LEAP the state space of each agent is initially decomposed into different partitions, each entrusted to a different Learning Entity (LE) that runs a Q-learning-like learning algorithm. Each partition aggregates states of the original state space into macrostates and for each macrostate, action pair the LE computes the Q-value and a measurement of the reliability of such a value. The learning process of LEAP is on-line and does not need any information about the transition model of the environment. The action selection phase is performed by a Learning Mediator (LM) that merges all the action-values learned by LEs through a simple mean of Q-values weighted by their variability, in order to strengthen only reliable estimations and then it computes the best action in the current state. During the update phase, each LE compares the expected reward with the target actually received and through a heuristic criterion, the consistency test, detects whether the resolution of its own partition in the current state should be increased, in that case the LE is said to be inconsistent. When more than one LE is inconsistent, the LM creates a new Joint Learning Entity (JLE), that will operate on a new single macrostate obtained as the intersection of the macrostates of the inconsistent LEs. As a result of the creation of such a new JLE, the basic LE will be deactivated on all the states covered by the more specialized entity. At the same time, an opposite mechanism, the pruning mechanism, detects, during the action selection, when a JLE can be removed from the list of LEs. This mechanism simply compares the action proposed by a JLE with the action that would be proposed by the deactivated LEs, and, when those actions are the same, the JLE can be removed. Through these mechanisms (consistency test and pruning), LEAP builds a multi-resolution state representation that is specialized only where it is needed to learn a near optimal policy, thus achieving good performances with short learning times. 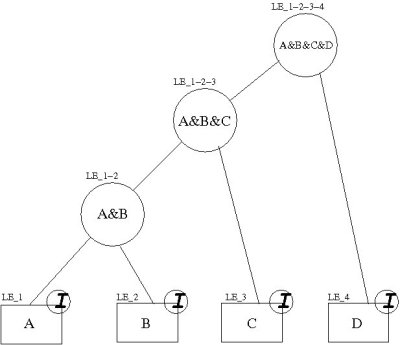
In order to overcome problems due to non-stationarity caused by the presence of several concurrently learning agents, we have added to LEAP a new category of Learning Entities, the Action Learning Entities (ALEs) characterized by a state space containing also information about the other agents' actions. In particular, each agent needs to create for each other agent two kinds of ALEs:
The information learned by ALEs is used in a negotiation process that leads to the selection of the joint action that maximize the common utility. |
Principal investigators
A. Lazaric,
M. Restelli
Research contributors
A. Bonarini,...